
20. 实现完整的 Transformer 模型#
20.1. Transformer 架构总览#
前面我们已经分别介绍了 Transformer 编码器和解码器的结构,现在我们将它们整合起来,构成完整的 Transformer 模型。完整的 Transformer 模型结构如下图所示:
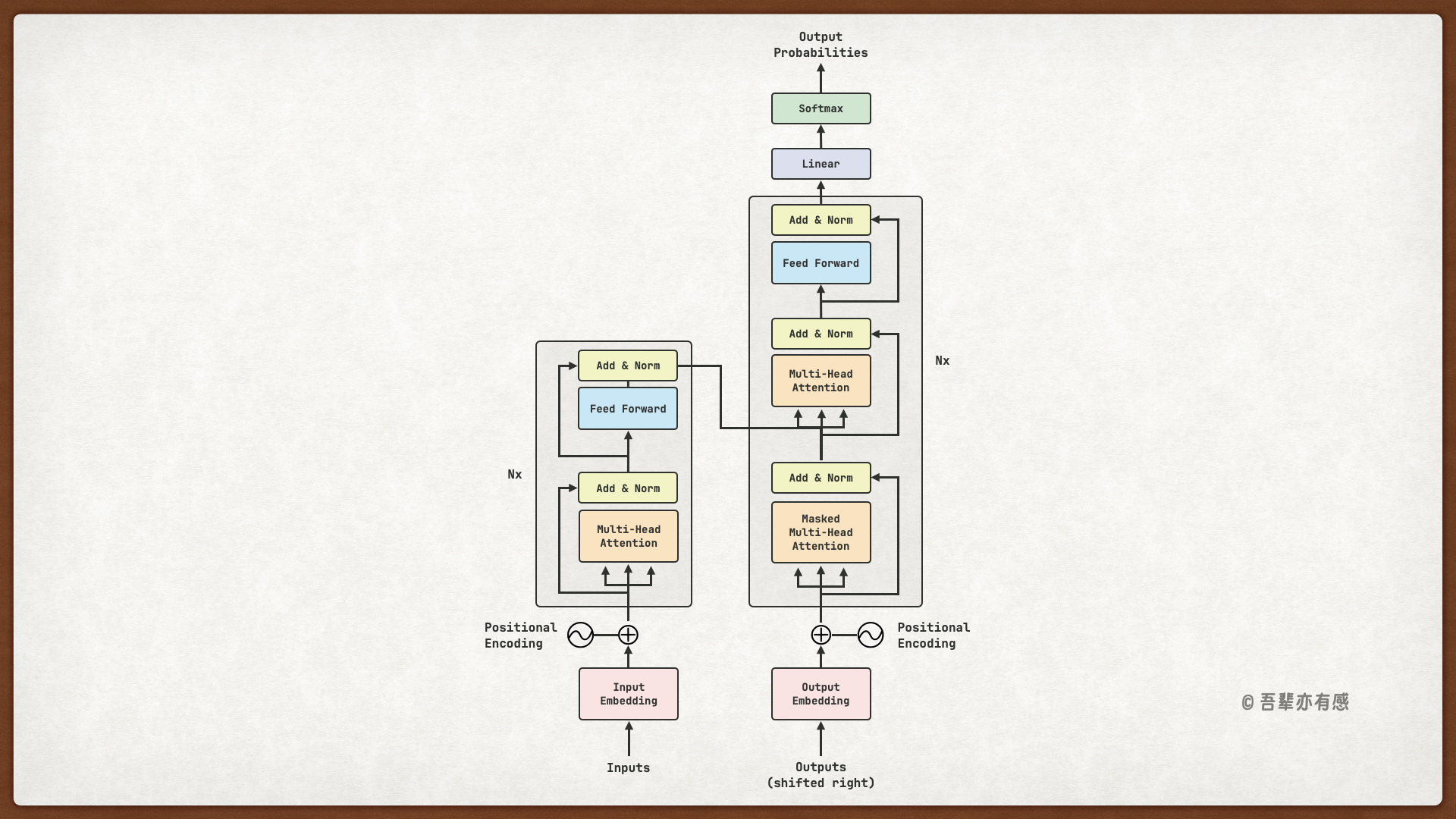
左侧和右侧分别对应着编码器(Encoder)和解码器(Decoder)结构。它们均由若干个基本的 Transformer 层组成(对应着图中的灰色框),这里 N 表示进行了 N 次堆叠。
下面我们使用已经实现好的 Transformer 组件构建编码器(Encoder)、解码器(Decoder)和完整的 Transformer 模型。在开始之前先准备运行环境和所需的数据。
20.2. 环境配置#
20.2.1. 安装依赖#
!pip install --upgrade dsxllm
20.2.2. 环境版本#
from dsxllm.util import show_version
show_version()
本书愿景:
+------+--------------------------------------------------------+
| Info | 《动手学大语言模型》 |
+------+--------------------------------------------------------+
| 作者 | 吾辈亦有感 |
| 哔站 | https://space.bilibili.com/3546632320715420 |
| 定位 | 基于'从零构建'的理念,用实战帮助程序员快速入门大模型。 |
| 愿景 | 若让你的AI学习之路走的更容易一点,我将倍感荣幸!祝好😄 |
+------+--------------------------------------------------------+
环境信息:
+-------------+--------------+------------------------+
| Python 版本 | PyTorch 版本 | PyTorch Lightning 版本 |
+-------------+--------------+------------------------+
| 3.12.12 | 2.10.0 | 2.6.1 |
+-------------+--------------+------------------------+
20.3. 数据准备#
from dsxllm.transformer.dataset import TextTransform, TextDataModule
from dsxllm.transformer.tokenizer import get_tokenizer
from dsxllm.util import print_red
# 超参配置
batch_size = 2
encoder_max_length = 7
decoder_max_length = 6
# 1️⃣ 初始化分词器
tokenizer = get_tokenizer()
# 2️⃣ 初始化数据转换
encoder_transform = TextTransform(tokenizer, max_length=encoder_max_length)
decoder_transform = TextTransform(tokenizer, max_length=decoder_max_length)
# 3️⃣ 加载数据模组
file_path = "./dataset/addition_train.txt"
datamodule = TextDataModule(
batch_size=batch_size,
encoder_transform=encoder_transform,
decoder_transform=decoder_transform,
train_data_file=file_path,
)
# 4️⃣ 调用 setup 方法初始化数据集
datamodule.setup()
# 5️⃣ 从数据加载器中获取一个批次的样本,供后续编码器和解码器使用
encoder_input_ids, decoder_input_ids, decoder_target_ids = None, None, None
questions, answers = None, None
for batch in datamodule.train_dataloader():
print(batch)
encoder_input_ids, decoder_input_ids, decoder_target_ids = (
batch["encoder_input_ids"],
batch["decoder_input_ids"],
batch["decoder_target_ids"],
)
questions = batch["question"]
answers = batch["answer"]
# 打印当前批次的样本
print_red("Encoder Input IDs:")
print(encoder_input_ids, "\n")
print_red("Decoder Input IDs:")
print(decoder_input_ids, "\n")
print_red("Decoder Target IDs:")
print(decoder_target_ids, "\n")
break
{'question': ['89+65', '71+685'], 'answer': ['154', '756'], 'encoder_input_ids': tensor([[ 8, 9, 10, 6, 5, 12, 12],
[ 7, 1, 10, 6, 8, 5, 12]]), 'encoder_pad_mask': tensor([[1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 0]]), 'decoder_input_ids': tensor([[14, 1, 5, 4, 15],
[14, 7, 5, 6, 15]]), 'decoder_pad_mask': tensor([[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]]), 'decoder_target_ids': tensor([[ 1, 5, 4, 15, 12],
[ 7, 5, 6, 15, 12]])}
Encoder Input IDs:
tensor([[ 8, 9, 10, 6, 5, 12, 12],
[ 7, 1, 10, 6, 8, 5, 12]])
Decoder Input IDs:
tensor([[14, 1, 5, 4, 15],
[14, 7, 5, 6, 15]])
Decoder Target IDs:
tensor([[ 1, 5, 4, 15, 12],
[ 7, 5, 6, 15, 12]])
20.4. 实现 Transformer Encoder 模型#
20.4.1. 定义编码器层(EncoderLayer)#
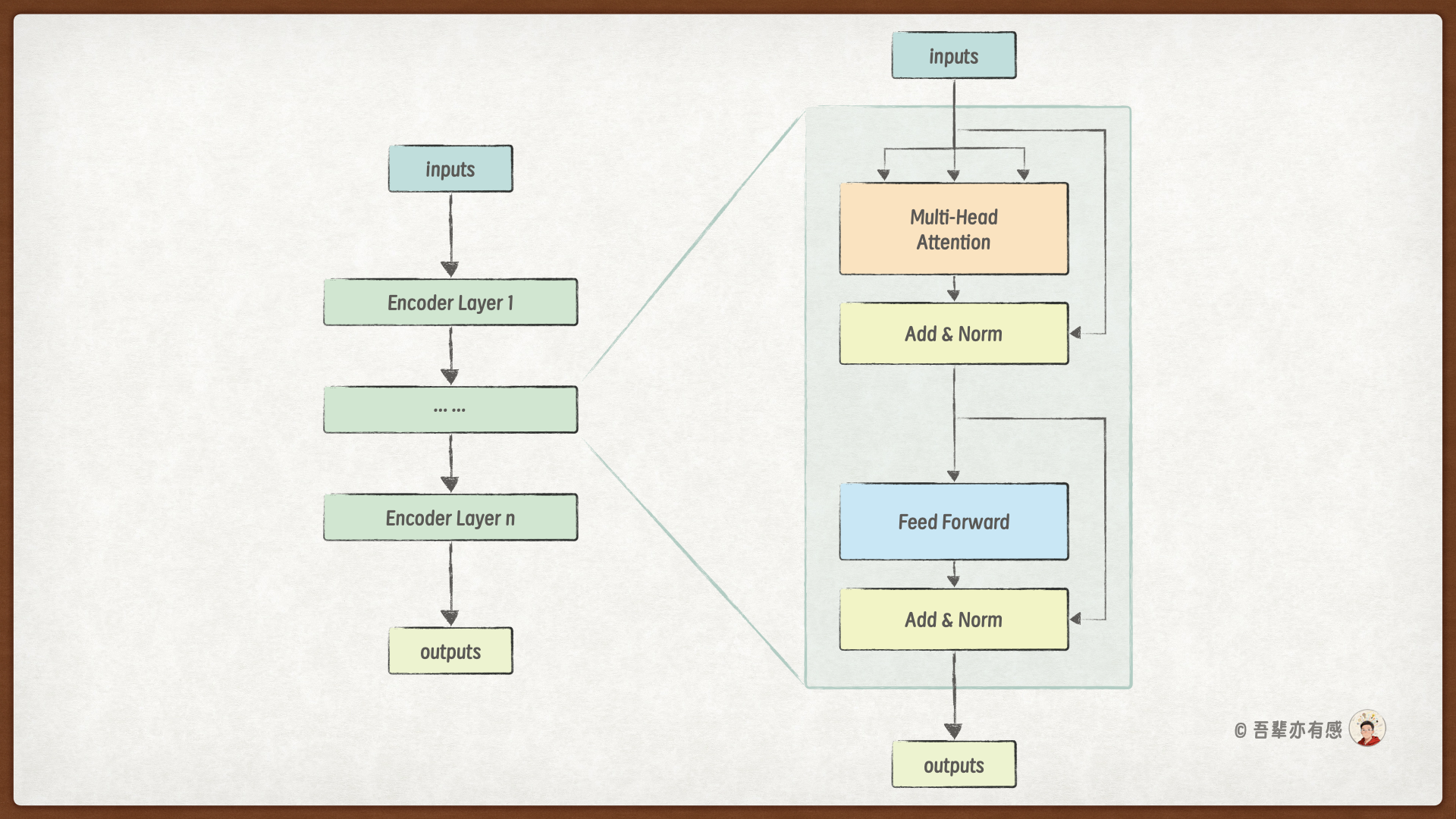
编码器层结构如下图所示,不过这里我们使用的是单头注意力机制,而不是多头注意力机制。
import torch
from torch import nn
from dsxllm.transformer.layers import SingleHeadAttention, LayerNorm, MLP
class EncoderLayer(nn.Module):
def __init__(self, d_model, feedforward_size):
super(EncoderLayer, self).__init__()
self.attn = SingleHeadAttention(d_model) # 自注意力层
self.attn_norm = LayerNorm(d_model) # 自注意力的归一化层
self.mlp = MLP(d_model, feedforward_size) # 前馈网络层
self.mlp_norm = LayerNorm(d_model) # 前馈网络的归一化层
def forward(self, hidden_states: torch.Tensor, mask=None):
# 对输入进行自注意力计算,并对结果进行残差连接和归一化
residual = hidden_states
hidden_states, _ = self.attn(q_input=hidden_states, k_input=hidden_states, v_input=hidden_states,
attn_mask=mask)
hidden_states = self.attn_norm(hidden_states + residual)
# 对输入进行前馈网络计算,并对结果进行残差连接和归一化
residual = hidden_states
hidden_states = self.mlp(hidden_states)
hidden_states = self.mlp_norm(hidden_states + residual)
return hidden_states
20.4.2. 查看编码器层(EncoderLayer)详情#
# 定义模型维度
d_model = 128
feedforward_size = d_model * 4
# 初始化编码器层
encoder_layer = EncoderLayer(d_model, feedforward_size)
# 打印编码器层结构
print(encoder_layer)
EncoderLayer(
(attn): SingleHeadAttention(
(q_proj): Linear(in_features=128, out_features=128, bias=False)
(k_proj): Linear(in_features=128, out_features=128, bias=False)
(v_proj): Linear(in_features=128, out_features=128, bias=False)
)
(attn_norm): LayerNorm()
(mlp): MLP(
(up_proj): Linear(in_features=128, out_features=512, bias=False)
(gate_proj): Linear(in_features=128, out_features=512, bias=False)
(down_proj): Linear(in_features=512, out_features=128, bias=False)
(act_fn): GELUActivation()
)
(mlp_norm): LayerNorm()
)
20.4.3. 定义编码器(Encoder)#
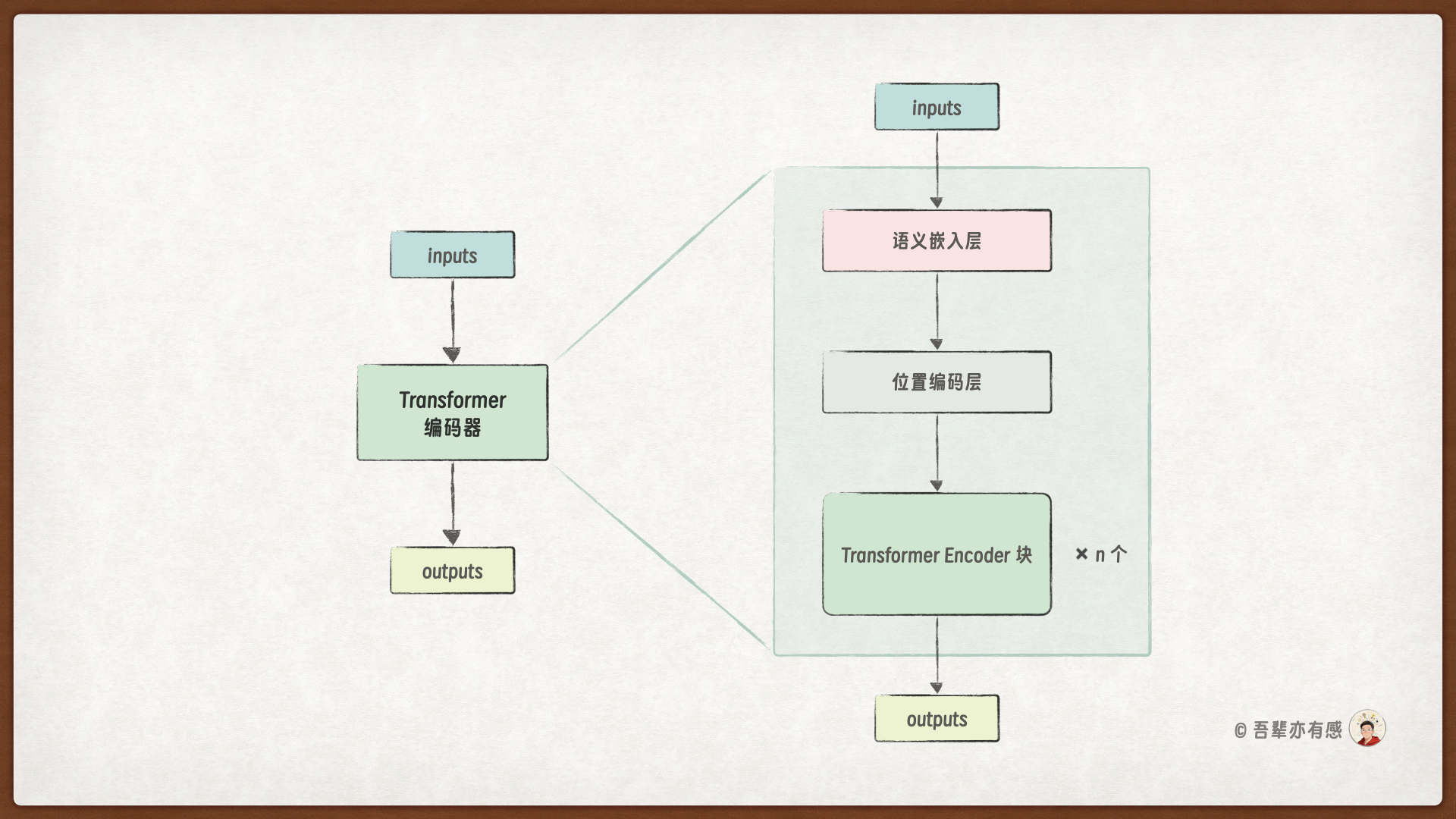
编码器结构如下图所示,它由语义嵌入层、位置编码层和多个编码器层组成,每个编码器层包含一个自注意力层和一个前馈神经网络层。
from torch import nn
from dsxllm.transformer.layers import PositionalEncoding, create_cross_attn_pad_mask
class Encoder(nn.Module):
def __init__(self, vocab_size, max_seq_len, d_model, feedforward_size, n_layers, pad_token_id):
super(Encoder, self).__init__()
self.pad_token_id = pad_token_id
self.token_emb = nn.Embedding(vocab_size, d_model) # 词嵌入层
self.position_emb = PositionalEncoding(d_model, max_seq_len) # 位置编码层
self.layers = nn.ModuleList([EncoderLayer(d_model, feedforward_size) for _ in range(n_layers)]) # 多层encoder
def forward(self, encoder_input_ids):
# encoder_inputs: [N, T]
encoder_outputs = self.token_emb(encoder_input_ids) # encoder_outputs: [N, T, D]
encoder_outputs = self.position_emb(encoder_outputs) # encoder_outputs: [N, T, D]
# # 生成Query和Key的交叉注意力填充mask矩阵,每个Query只关注非填充的Key,只与其计算注意力得分: [N, T, T]
encoder_attn_pad_mask = create_cross_attn_pad_mask(query_ids=encoder_input_ids, key_ids=encoder_input_ids,
pad_token_id=self.pad_token_id)
for layer in self.layers:
encoder_outputs = layer(encoder_outputs, encoder_attn_pad_mask)
# 数据的形状为 [批次大小, 序列长度, 模型维度]
return encoder_outputs
20.4.4. 初始化编码器(Encoder)实例#
from dsxllm.util import print_red
# 定义模型参数
vocab_size = tokenizer.vocab_size # 词汇表大小
d_model = 128 # 模型维度
feedforward_size = 512 # 前馈神经网络维度
n_layers = 4 # 编码器层数量
pad_token_id = tokenizer.pad_token_id # 填充token id
max_seq_len = 512 # 最大序列长度
# 初始化编码器模型
encoder = Encoder(
vocab_size=vocab_size,
max_seq_len=max_seq_len,
d_model=d_model,
feedforward_size=feedforward_size,
n_layers=n_layers,
pad_token_id=pad_token_id,
)
# 打印编码器模型结构
print_red("编码器模型结构: ")
print(encoder)
编码器模型结构:
Encoder(
(token_emb): Embedding(16, 128)
(position_emb): PositionalEncoding()
(layers): ModuleList(
(0-3): 4 x EncoderLayer(
(attn): SingleHeadAttention(
(q_proj): Linear(in_features=128, out_features=128, bias=False)
(k_proj): Linear(in_features=128, out_features=128, bias=False)
(v_proj): Linear(in_features=128, out_features=128, bias=False)
)
(attn_norm): LayerNorm()
(mlp): MLP(
(up_proj): Linear(in_features=128, out_features=512, bias=False)
(gate_proj): Linear(in_features=128, out_features=512, bias=False)
(down_proj): Linear(in_features=512, out_features=128, bias=False)
(act_fn): GELUActivation()
)
(mlp_norm): LayerNorm()
)
)
)
20.4.5. 查看编码器(Encoder)详情#
from torchinfo import summary
print_red("编码器的详细信息: ")
print(summary(encoder, input_data=encoder_input_ids, col_names=["input_size", "output_size", "num_params"]))
Encoder Model:
========================================================================================================================
Layer (type:depth-idx) Input Shape Output Shape Param #
========================================================================================================================
Encoder [2, 7] [2, 7, 128] --
├─Embedding: 1-1 [2, 7] [2, 7, 128] 2,048
├─PositionalEncoding: 1-2 [2, 7, 128] [2, 7, 128] --
├─ModuleList: 1-3 -- -- --
│ └─EncoderLayer: 2-1 [2, 7, 128] [2, 7, 128] --
│ │ └─SingleHeadAttention: 3-1 -- [2, 7, 128] 49,152
│ │ └─LayerNorm: 3-2 [2, 7, 128] [2, 7, 128] 256
│ │ └─MLP: 3-3 [2, 7, 128] [2, 7, 128] 196,608
│ │ └─LayerNorm: 3-4 [2, 7, 128] [2, 7, 128] 256
│ └─EncoderLayer: 2-2 [2, 7, 128] [2, 7, 128] --
│ │ └─SingleHeadAttention: 3-5 -- [2, 7, 128] 49,152
│ │ └─LayerNorm: 3-6 [2, 7, 128] [2, 7, 128] 256
│ │ └─MLP: 3-7 [2, 7, 128] [2, 7, 128] 196,608
│ │ └─LayerNorm: 3-8 [2, 7, 128] [2, 7, 128] 256
│ └─EncoderLayer: 2-3 [2, 7, 128] [2, 7, 128] --
│ │ └─SingleHeadAttention: 3-9 -- [2, 7, 128] 49,152
│ │ └─LayerNorm: 3-10 [2, 7, 128] [2, 7, 128] 256
│ │ └─MLP: 3-11 [2, 7, 128] [2, 7, 128] 196,608
│ │ └─LayerNorm: 3-12 [2, 7, 128] [2, 7, 128] 256
│ └─EncoderLayer: 2-4 [2, 7, 128] [2, 7, 128] --
│ │ └─SingleHeadAttention: 3-13 -- [2, 7, 128] 49,152
│ │ └─LayerNorm: 3-14 [2, 7, 128] [2, 7, 128] 256
│ │ └─MLP: 3-15 [2, 7, 128] [2, 7, 128] 196,608
│ │ └─LayerNorm: 3-16 [2, 7, 128] [2, 7, 128] 256
========================================================================================================================
Total params: 987,136
Trainable params: 987,136
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 1.97
========================================================================================================================
Input size (MB): 0.00
Forward/backward pass size (MB): 0.82
Params size (MB): 3.95
Estimated Total Size (MB): 4.77
========================================================================================================================
20.4.6. 使用编码器(Encoder)进行计算#
from dsxllm.util import print_table
# 编码器前向传播
encoder_outputs = encoder(encoder_input_ids)
# 打印编码器输入和输出的形状信息,方便调试和学习
print_table("编码器输入和输出", field_names=["Tensor", "Shape", "Note"], data=[
["Encoder Inputs Shape", encoder_input_ids.shape, "(batch_size, encoder_seq_len)"],
["Encoder Outputs Shape", encoder_outputs.shape, "(batch_size, encoder_seq_len, d_model)"]
])
编码器输入和输出:
+-----------------------+-------------------------+----------------------------------------+
| Tensor | Shape | Note |
+-----------------------+-------------------------+----------------------------------------+
| Encoder Inputs Shape | torch.Size([2, 7]) | (batch_size, encoder_seq_len) |
| Encoder Outputs Shape | torch.Size([2, 7, 128]) | (batch_size, encoder_seq_len, d_model) |
+-----------------------+-------------------------+----------------------------------------+
20.5. 实现 Transformer Decoder 模型#
20.5.1. 定义解码器层(DecoderLayer)#
Transformer 解码器层包含以下三个子层:因果自注意力层、编码器-解码器交叉自注意力层以及前馈神经网络层。同时,每个子层都包含残差连接和层归一化来提高模型训练的稳定性。具体结构如下图所示:
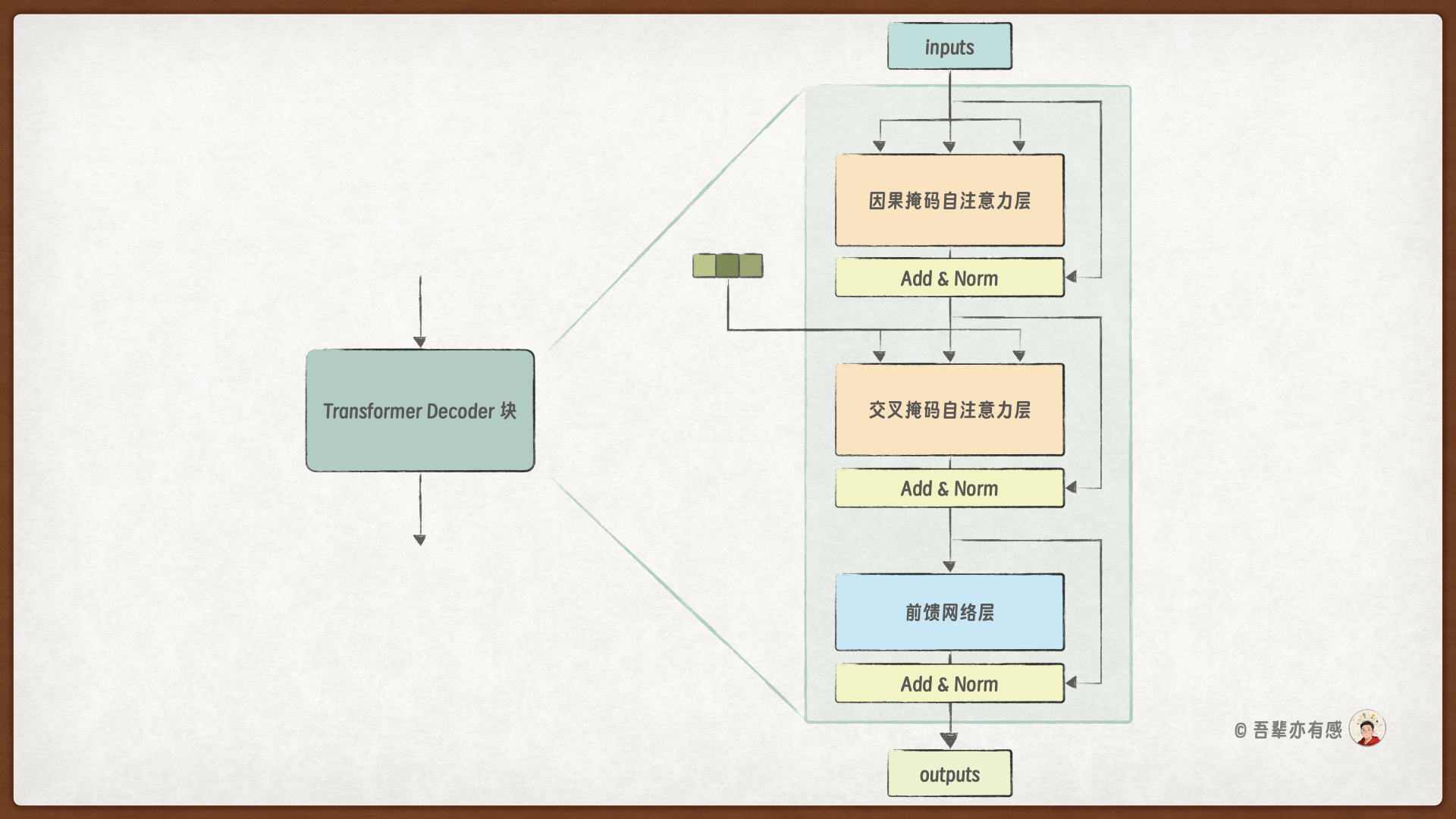
和解码器一样,这里的两个自注意力层我们依然使用单头自注意力层代替多头自注意力层。
import torch
from torch import nn
from dsxllm.transformer.layers import SingleHeadAttention, LayerNorm, MLP
class DecoderLayer(nn.Module):
def __init__(self, d_model, feedforward_size):
super(DecoderLayer, self).__init__()
self.self_attn = SingleHeadAttention(d_model) # 自注意力层
self.attn_norm = LayerNorm(d_model)
self.cross_attn = SingleHeadAttention(d_model) # 交叉自注意力层
self.cross_attn_norm = LayerNorm(d_model)
self.mlp = MLP(d_model, feedforward_size) # 前馈网络层
self.mlp_norm = LayerNorm(d_model)
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
# 残差
residual = dec_inputs
# 自注意力计算
dec_outputs, _ = self.self_attn(dec_inputs, dec_inputs, dec_inputs,
dec_self_attn_mask)
# 残差连接 + 层归一化
dec_outputs = self.attn_norm(dec_outputs + residual)
# 残差
residual = dec_outputs
# 交叉注意力计算
dec_outputs, _ = self.cross_attn(dec_outputs, enc_outputs,
enc_outputs, dec_enc_attn_mask)
# 残差连接 + 层归一化
dec_outputs = self.cross_attn_norm(dec_outputs + residual)
# 残差
residual = dec_outputs
# 前馈网络计算
dec_outputs = self.mlp(dec_outputs)
# 残差连接 + 层归一化
dec_outputs = self.mlp_norm(dec_outputs + residual)
return dec_outputs
20.5.2. 查看解码器层(DecoderLayer)详情#
# 定义解码器参数
d_model = 128 # 模型维度
feedforward_size = 512 # 前馈网络维度
# 初始化解码器层
decoder_layer = DecoderLayer(d_model, feedforward_size)
# 打印解码器层结构
print_red("解码器模型结构: ")
print(decoder_layer)
解码器模型结构:
DecoderLayer(
(self_attn): SingleHeadAttention(
(q_proj): Linear(in_features=128, out_features=128, bias=False)
(k_proj): Linear(in_features=128, out_features=128, bias=False)
(v_proj): Linear(in_features=128, out_features=128, bias=False)
)
(attn_norm): LayerNorm()
(cross_attn): SingleHeadAttention(
(q_proj): Linear(in_features=128, out_features=128, bias=False)
(k_proj): Linear(in_features=128, out_features=128, bias=False)
(v_proj): Linear(in_features=128, out_features=128, bias=False)
)
(cross_attn_norm): LayerNorm()
(mlp): MLP(
(up_proj): Linear(in_features=128, out_features=512, bias=False)
(gate_proj): Linear(in_features=128, out_features=512, bias=False)
(down_proj): Linear(in_features=512, out_features=128, bias=False)
(act_fn): GELUActivation()
)
(mlp_norm): LayerNorm()
)
20.5.3. 定义解码器(Decoder)#
编码器结构如下图所示,它由语义嵌入层、位置编码层、多个编码器层以及输出层组成。
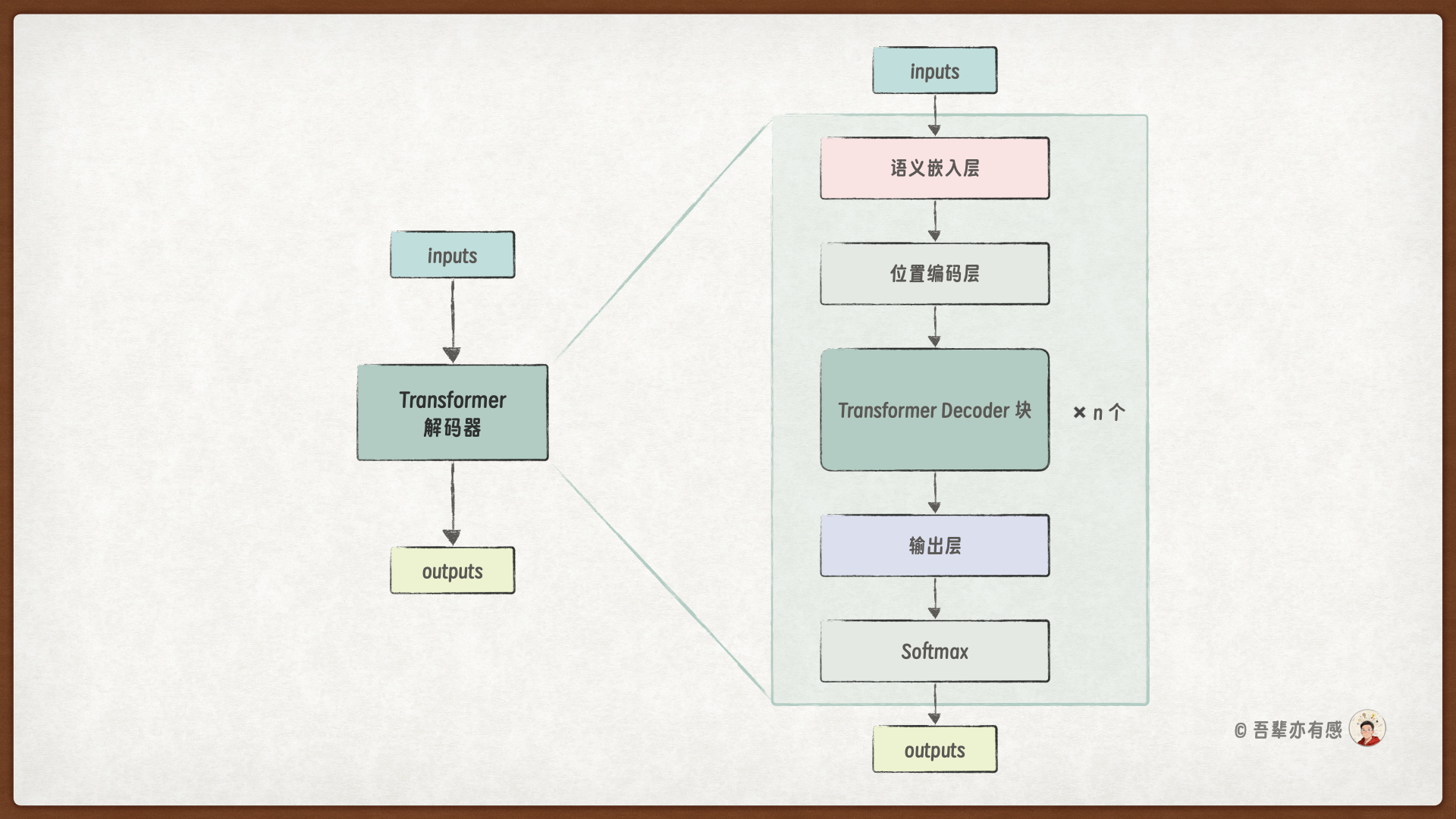
from dsxllm.transformer.layers import create_causal_attn_mask
class Decoder(nn.Module):
def __init__(self, vocab_size, max_seq_len, d_model, feedforward_size, n_layers, pad_token_id):
super(Decoder, self).__init__()
# 解码器的vocab_size可以和编码器是不同的(例如:翻译任务)
self.pad_token_id = pad_token_id
self.token_emb = nn.Embedding(vocab_size, d_model)
self.position_emb = PositionalEncoding(d_model, max_seq_len)
self.layers = nn.ModuleList([DecoderLayer(d_model, feedforward_size) for _ in range(n_layers)])
self.output_layer = nn.Linear(d_model, vocab_size)
def forward(self, dec_inputs, enc_inputs, enc_outputs):
dec_outputs = self.token_emb(dec_inputs) # [batch_size, tgt_len, d_model]
dec_outputs = self.position_emb(dec_outputs) # [batch_size, tgt_len, d_model]
# 生成解码器输入的填充掩码矩阵
dec_self_attn_pad_mask = create_cross_attn_pad_mask(dec_inputs, dec_inputs,
self.pad_token_id).to(dec_inputs.device)
# print("dec_self_attn_pad_mask ->\n", dec_self_attn_pad_mask, "\n")
# 生成解码器输入的causal mask矩阵
dec_self_attn_subsequence_mask = create_causal_attn_mask(dec_inputs).to(dec_inputs.device)
# print("dec_self_attn_subsequence_mask ->\n", dec_self_attn_subsequence_mask, "\n")
# 通过逻辑与运算,生成解码器输入最终的掩码矩阵
dec_self_attn_mask = torch.logical_and(dec_self_attn_pad_mask, dec_self_attn_subsequence_mask).byte().to(
dec_inputs.device)
# print("dec_self_attn_mask ->\n", dec_self_attn_mask, "\n")
# 生成编码器和解码器的交叉注意力矩阵
dec_enc_attn_mask = create_cross_attn_pad_mask(dec_inputs, enc_inputs, self.pad_token_id).to(dec_inputs.device)
# print("dec_enc_attn_mask ->\n", dec_enc_attn_mask, "\n")
# 遍历解码器层
for layer in self.layers:
dec_outputs = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
# 使用输出层将解码器输出映射到词汇表大小
dec_outputs = self.output_layer(dec_outputs)
return dec_outputs
20.5.4. 初始化解码器(Decoder)实例#
# 定义解码器参数
vocab_size = tokenizer.vocab_size # 词汇表大小
d_model = 128 # 模型维度
feedforward_size = 512 # 前馈网络维度
n_layers = 4 # 解码器层数量
pad_token_id = tokenizer.pad_token_id # 填充token id
# 初始化解码器
decoder = Decoder(
vocab_size=vocab_size,
max_seq_len=512,
d_model=d_model,
feedforward_size=feedforward_size,
n_layers=n_layers,
pad_token_id=pad_token_id,
)
# 打印解码器模型结构
print_red("解码器模型结构: ")
print(decoder)
解码器模型结构:
Decoder(
(token_emb): Embedding(16, 128)
(position_emb): PositionalEncoding()
(layers): ModuleList(
(0-3): 4 x DecoderLayer(
(self_attn): SingleHeadAttention(
(q_proj): Linear(in_features=128, out_features=128, bias=False)
(k_proj): Linear(in_features=128, out_features=128, bias=False)
(v_proj): Linear(in_features=128, out_features=128, bias=False)
)
(attn_norm): LayerNorm()
(cross_attn): SingleHeadAttention(
(q_proj): Linear(in_features=128, out_features=128, bias=False)
(k_proj): Linear(in_features=128, out_features=128, bias=False)
(v_proj): Linear(in_features=128, out_features=128, bias=False)
)
(cross_attn_norm): LayerNorm()
(mlp): MLP(
(up_proj): Linear(in_features=128, out_features=512, bias=False)
(gate_proj): Linear(in_features=128, out_features=512, bias=False)
(down_proj): Linear(in_features=512, out_features=128, bias=False)
(act_fn): GELUActivation()
)
(mlp_norm): LayerNorm()
)
)
(output_layer): Linear(in_features=128, out_features=16, bias=True)
)
20.5.5. 查看解码器(Decoder)详情#
from torchinfo import summary
print_red("解码器模型的详细信息: ")
summary(decoder, input_data=(decoder_input_ids, encoder_input_ids, encoder_outputs),
col_names=["input_size", "output_size", "num_params"])
解码器模型的详细信息:
========================================================================================================================
Layer (type:depth-idx) Input Shape Output Shape Param #
========================================================================================================================
Decoder [2, 5] [2, 5, 16] --
├─Embedding: 1-1 [2, 5] [2, 5, 128] 2,048
├─PositionalEncoding: 1-2 [2, 5, 128] [2, 5, 128] --
├─ModuleList: 1-3 -- -- --
│ └─DecoderLayer: 2-1 [2, 5, 128] [2, 5, 128] --
│ │ └─SingleHeadAttention: 3-1 [2, 5, 128] [2, 5, 128] 49,152
│ │ └─LayerNorm: 3-2 [2, 5, 128] [2, 5, 128] 256
│ │ └─SingleHeadAttention: 3-3 [2, 5, 128] [2, 5, 128] 49,152
│ │ └─LayerNorm: 3-4 [2, 5, 128] [2, 5, 128] 256
│ │ └─MLP: 3-5 [2, 5, 128] [2, 5, 128] 196,608
│ │ └─LayerNorm: 3-6 [2, 5, 128] [2, 5, 128] 256
│ └─DecoderLayer: 2-2 [2, 5, 128] [2, 5, 128] --
│ │ └─SingleHeadAttention: 3-7 [2, 5, 128] [2, 5, 128] 49,152
│ │ └─LayerNorm: 3-8 [2, 5, 128] [2, 5, 128] 256
│ │ └─SingleHeadAttention: 3-9 [2, 5, 128] [2, 5, 128] 49,152
│ │ └─LayerNorm: 3-10 [2, 5, 128] [2, 5, 128] 256
│ │ └─MLP: 3-11 [2, 5, 128] [2, 5, 128] 196,608
│ │ └─LayerNorm: 3-12 [2, 5, 128] [2, 5, 128] 256
│ └─DecoderLayer: 2-3 [2, 5, 128] [2, 5, 128] --
│ │ └─SingleHeadAttention: 3-13 [2, 5, 128] [2, 5, 128] 49,152
│ │ └─LayerNorm: 3-14 [2, 5, 128] [2, 5, 128] 256
│ │ └─SingleHeadAttention: 3-15 [2, 5, 128] [2, 5, 128] 49,152
│ │ └─LayerNorm: 3-16 [2, 5, 128] [2, 5, 128] 256
│ │ └─MLP: 3-17 [2, 5, 128] [2, 5, 128] 196,608
│ │ └─LayerNorm: 3-18 [2, 5, 128] [2, 5, 128] 256
│ └─DecoderLayer: 2-4 [2, 5, 128] [2, 5, 128] --
│ │ └─SingleHeadAttention: 3-19 [2, 5, 128] [2, 5, 128] 49,152
│ │ └─LayerNorm: 3-20 [2, 5, 128] [2, 5, 128] 256
│ │ └─SingleHeadAttention: 3-21 [2, 5, 128] [2, 5, 128] 49,152
│ │ └─LayerNorm: 3-22 [2, 5, 128] [2, 5, 128] 256
│ │ └─MLP: 3-23 [2, 5, 128] [2, 5, 128] 196,608
│ │ └─LayerNorm: 3-24 [2, 5, 128] [2, 5, 128] 256
├─Linear: 1-4 [2, 5, 128] [2, 5, 16] 2,064
========================================================================================================================
Total params: 1,186,832
Trainable params: 1,186,832
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 2.37
========================================================================================================================
Input size (MB): 0.01
Forward/backward pass size (MB): 0.78
Params size (MB): 4.75
Estimated Total Size (MB): 5.54
========================================================================================================================
20.5.6. 使用解码器(Decoder)进行计算#
# 基于编码器的输出和解码器输入,计算解码器输出
decoder_outputs = decoder(decoder_input_ids, encoder_input_ids, encoder_outputs)
# 解码器输入
print_table(table_name="解码器输入",
field_names=["Tensor", "Shape"],
data=[["decoder_input_ids", decoder_input_ids.shape],
["encoder_input_ids", encoder_input_ids.shape],
["encoder_outputs", encoder_outputs.shape]])
# 解码器输出
print_table(table_name="解码器输出",
field_names=["Tensor", "Shape"],
data=[["decoder_outputs", decoder_outputs.shape]])
解码器输入:
+-------------------+-------------------------+
| Tensor | Shape |
+-------------------+-------------------------+
| decoder_input_ids | torch.Size([2, 5]) |
| encoder_input_ids | torch.Size([2, 7]) |
| encoder_outputs | torch.Size([2, 7, 128]) |
+-------------------+-------------------------+
解码器输出:
+-----------------+------------------------+
| Tensor | Shape |
+-----------------+------------------------+
| decoder_outputs | torch.Size([2, 5, 16]) |
+-----------------+------------------------+
20.6. 实现完整的 Transformer 模型#
20.6.1. 定义 Transformer 模型#
串联编码器和解码器构建完整的 Transformer 模型,并且实现模型的训练和评估流程。
from dsxllm.transformer.tokenizer import TransformerTokenizer
import lightning as L
class Transformer(L.LightningModule):
"""
序列到序列的Transformer模型,继承自LightningModule,集成了训练、验证、生成等功能。
包含编码器(Encoder)和解码器(Decoder),并提供了训练步骤、验证步骤、优化器配置、
批量生成以及指标记录等完整流程。
"""
def __init__(
self,
tokenizer: TransformerTokenizer,
d_model,
feedforward_size,
encoder_max_length,
decoder_max_length,
n_layers=1,
learning_rate=0.0001,
):
"""
初始化Transformer模型,包含编码器(Encoder)和解码器(Decoder)。
参数:
tokenizer: 分词器实例,用于处理词汇表、特殊token等
d_model: 模型的维度(编码器和解码器的隐藏层维度)
feedforward_size: 前馈网络的隐藏层维度
encoder_max_length: 编码器输入的最大序列长度
decoder_max_length: 解码器输入的最大序列长度
n_layers: 编码器和解码器的层数(默认1层)
learning_rate: 学习率(默认0.0001)
"""
super(Transformer, self).__init__()
# 初始化编码器
self.encoder = Encoder(
vocab_size=tokenizer.vocab_size,
max_seq_len=encoder_max_length,
d_model=d_model,
feedforward_size=feedforward_size,
n_layers=n_layers,
pad_token_id=tokenizer.pad_token_id,
)
# 初始化解码器
self.decoder = Decoder(
vocab_size=tokenizer.vocab_size,
max_seq_len=decoder_max_length,
d_model=d_model,
feedforward_size=feedforward_size,
n_layers=n_layers,
pad_token_id=tokenizer.pad_token_id,
)
# 保存分词器和其他超参数
self.tokenizer = tokenizer
self.learning_rate = learning_rate
self.encoder_max_length = encoder_max_length
self.decoder_max_length = decoder_max_length
# 示例输入
self.example_input_array = (
torch.randint(
0, tokenizer.vocab_size, (2, encoder_max_length), dtype=torch.long
),
torch.randint(
0, tokenizer.vocab_size, (2, decoder_max_length), dtype=torch.long
),
)
# 用于存储训练和验证过程中的指标
self.train_step_losses = []
self.train_epoch_losses = []
self.validation_step_outputs = []
self.validation_epoch_outputs = []
def forward(self, encoder_input_ids, decoder_input_ids):
"""
前向传播:编码器处理输入,解码器结合编码器输出生成预测。
:param encoder_input_ids: 编码器输入token IDs,形状 (batch_size, encoder_max_length)
:param decoder_input_ids: 解码器输入token IDs,形状 (batch_size, decoder_max_length)
:return: 解码器输出的logits,形状 (batch_size, decoder_max_length, vocab_size)
"""
# 编码器前向传播,得到编码器输出(通常为最后一个隐藏状态或所有层的输出)
encoder_outputs = self.encoder(encoder_input_ids)
# 解码器前向传播,使用编码器输出和编码器输入(用于交叉注意力)以及解码器输入
decoder_outputs = self.decoder(
decoder_input_ids, encoder_input_ids, encoder_outputs
)
return decoder_outputs
def training_step(self, batch, batch_idx):
"""
单个训练step的操作:计算loss并记录。
:param batch: 一个batch的数据,包含 'encoder_input_ids', 'decoder_input_ids', 'decoder_target_ids'
:param batch_idx: batch索引
:return: loss张量,用于反向传播
"""
# 从batch中取出编码器和解码器输入
encoder_input_ids, decoder_input_ids = (
batch["encoder_input_ids"],
batch["decoder_input_ids"],
)
# 前向传播得到解码器logits
decoder_outputs = self(encoder_input_ids, decoder_input_ids)
# 解码器目标输出(真实的target IDs,通常右移一位用于训练)
decoder_target_ids = batch["decoder_target_ids"]
# 计算交叉熵损失:将logits reshape为 (batch_size * seq_len, vocab_size),
# 目标reshape为 (batch_size * seq_len,),忽略填充位置的损失(由损失函数内部处理填充)
loss = torch.nn.functional.cross_entropy(
decoder_outputs.view(-1, decoder_outputs.shape[-1]), # 合并batch和序列维度
decoder_target_ids.view(-1), # 同样合并
)
# 保存当前step的loss(detach避免计算图累积)
self.train_step_losses.append(loss.detach())
return loss
def on_train_epoch_end(self):
"""在每个训练epoch结束时计算整体损失"""
if self.train_step_losses: # 确保列表不为空
# 计算并记录平均训练损失
avg_train_loss = torch.stack(self.train_step_losses).mean()
print(
f"***** 【Epoch {self.current_epoch}】 Train Avg Loss: {avg_train_loss:.4f} *****"
)
self.train_epoch_losses.append(
{"epoch": self.current_epoch, "loss": avg_train_loss.item()}
)
# 清空列表为下一个 epoch 做准备
self.train_step_losses.clear()
def validation_step(self, batch, batch_idx):
"""
单个验证step的操作:计算准确率等指标并保存中间结果。
:param batch: 一个batch的数据,包含编码器输入、解码器输入、解码器目标
:param batch_idx: batch索引
"""
encoder_input_ids = batch["encoder_input_ids"]
decoder_input_ids = batch["decoder_input_ids"]
decoder_target_ids = batch["decoder_target_ids"]
# 前向传播
outputs = self(encoder_input_ids, decoder_input_ids)
# 获取每个位置概率最高的token作为预测值
preds = torch.argmax(outputs, dim=-1) # 形状 (batch_size, decoder_max_length)
# 创建掩码,标记目标序列中非填充的位置(用于计算token准确率)
mask = decoder_target_ids != self.tokenizer.pad_token_id
# 计算token级别的准确率
correct_tokens = (
((preds == decoder_target_ids) & mask).sum().float()
) # 正确预测的非填充token数
total_tokens = mask.sum().float() # 所有非填充token数
token_acc = (
correct_tokens / total_tokens if total_tokens > 0 else torch.tensor(0.0)
)
# 计算序列级别的准确率:一个序列中所有非填充位置都预测正确才算正确
# (preds == decoder_target_ids) 比较预测和目标,~mask 将填充位置视为True(因为填充位置不参与比较)
# 然后在序列维度上所有位置都为True(all(dim=1))则该序列正确,最后取平均得到序列准确率
seq_correct = ((preds == decoder_target_ids) | ~mask).all(dim=1).float().mean()
# 保存当前step的输出,供epoch结束时汇总
self.validation_step_outputs.append(
{
"preds": preds, # 预测的token IDs
"target_ids": decoder_target_ids, # 目标token IDs
"token_acc": token_acc, # 当前batch的token准确率(标量)
"seq_acc": seq_correct, # 当前batch的序列准确率(标量)
}
)
def on_validation_epoch_end(self):
"""在每个验证epoch结束时计算整体准确率"""
# 汇总所有预测结果和标签
all_preds = torch.cat([x["preds"] for x in self.validation_step_outputs])
all_target_ids = torch.cat(
[x["target_ids"] for x in self.validation_step_outputs]
)
# 1. 计算序列(样本)级别的准确率
# 创建掩码以标识非填充位置
mask = all_target_ids != self.tokenizer.pad_token_id
# 计算每个序列是否完全正确(所有非填充位置都预测正确)
seq_correct = ((all_preds == all_target_ids) | ~mask).all(dim=1)
# 序列总数
total_sequences = all_preds.size(0)
# 正确预测的序列数
correct_sequences = seq_correct.sum().item()
# 序列级别准确率
seq_acc = correct_sequences / total_sequences if total_sequences > 0 else 0.0
print_red(
f"***** Validation: 样本总数 {total_sequences} 正确预测: {correct_sequences} 正确率: {seq_acc:.4f} *****"
)
# 2. 计算 Token 级别的准确率
# 计算所有非填充位置的预测总数
total_tokens = mask.sum().item()
# 计算所有非填充位置预测正确的总数
correct_tokens = ((all_preds == all_target_ids) & mask).sum().item()
# Token 级别准确率
token_acc = correct_tokens / total_tokens if total_tokens > 0 else 0.0
# 3. 将评估结果保存到 validation_epoch_outputs 列表中
self.validation_epoch_outputs.append(
{
"epoch": self.current_epoch,
"总样本数": total_sequences,
"正确样本数": correct_sequences,
"样本准确率": round(seq_acc, 4),
"总Token数": total_tokens,
"正确Token数": correct_tokens,
"Token准确率": round(token_acc, 4),
}
)
# 记录日志
self.log("total_sequences", total_sequences)
self.log("correct_sequences", correct_sequences)
self.log("seq_acc", seq_acc)
self.log("total_tokens", total_tokens)
self.log("correct_tokens", correct_tokens)
self.log("token_acc", token_acc)
# 清空缓存
self.validation_step_outputs.clear()
def clear_cache(self):
"""清除缓存"""
self.train_step_losses.clear()
self.train_epoch_losses.clear()
self.validation_step_outputs.clear()
self.validation_epoch_outputs.clear()
def configure_optimizers(self):
"""配置优化器"""
optimizer = torch.optim.Adam(self.parameters(), lr=self.learning_rate)
return optimizer
def generate(self, encoder_input_ids):
"""
单样本生成(greedy decoding),用于推理。
:param encoder_input_ids: 编码器输入,形状 (seq_len,) 或 (1, seq_len),这里假设是(seq_len,)
:return: 解码后的字符串
"""
# 增加batch维度,变为 (1, seq_len)
encoder_input_ids = encoder_input_ids.unsqueeze(0)
# 编码器前向传播
enc_outputs = self.encoder(encoder_input_ids)
# 初始化解码器输入,全部填充为pad_token_id,形状 (1, decoder_max_length)
dec_input = torch.full(
(1, self.decoder_max_length),
self.tokenizer.pad_token_id,
device=encoder_input_ids.device,
dtype=torch.long,
)
# 第一个要生成的token设为BOS(开始标记)
next_token = self.tokenizer.bos_token_id
# 逐位置生成
for i in range(self.decoder_max_length):
# 将当前预测的next_token放入解码器输入的正确位置
dec_input[0][i] = next_token
# 解码器前向传播,得到当前所有位置的logits
projected = self.decoder(dec_input, encoder_input_ids, enc_outputs)
# 取最后一个位置(当前位置)的概率分布,并取最大值的索引作为下一个token
prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]
next_word = prob.data[i] # 取出第i个位置的结果
next_token = next_word.item() # 转为Python整数
# 将生成的token序列解码为字符串(忽略填充部分)
preds = self.tokenizer.decode(dec_input[0].tolist())
return preds
def generate_batch(self, encoder_input_ids):
"""
批量生成(greedy decoding),支持同时生成多个样本。
:param encoder_input_ids: 编码器输入,形状 (batch_size, encoder_max_length)
:return: 解码后的字符串列表,长度为batch_size
"""
batch_size = encoder_input_ids.shape[0]
# 编码器前向传播
encoder_outputs = self.encoder(encoder_input_ids)
# 初始化解码器输入,全部填充为pad_token_id,形状 (batch_size, decoder_max_length)
decoder_input_ids = torch.full(
(batch_size, self.decoder_max_length),
self.tokenizer.pad_token_id,
device=encoder_outputs.device,
dtype=torch.long,
)
# 将每个序列的第一个位置设置为BOS标记
decoder_input_ids[:, 0] = self.tokenizer.bos_token_id
# 逐步生成每个后续位置
for i in range(
1, self.decoder_max_length
): # 从位置1开始,因为位置0已经设置为BOS
# 获取当前已生成序列的预测结果(解码器前向传播)
decoder_outputs = self.decoder(
dec_inputs=decoder_input_ids,
enc_inputs=encoder_input_ids,
enc_outputs=encoder_outputs,
)
# 获取当前位置(i-1位置)的预测概率分布
# 注意:decoder_outputs 形状为 (batch_size, decoder_max_length, vocab_size)
# 使用前一个位置的输出(i-1)来预测当前位置(i)的token
current_logits = decoder_outputs[:, i - 1, :] # [batch_size, vocab_size]
# 选择概率最高的token作为下一个token
next_tokens = torch.argmax(current_logits, dim=-1) # [batch_size]
# 将预测的token填入解码器输入的第i个位置
decoder_input_ids[:, i] = next_tokens
# 如果所有序列都生成了EOS(结束标记),则提前终止生成
if torch.all(next_tokens == self.tokenizer.eos_token_id):
break
# 将每个序列解码为字符串
preds = []
for i in range(batch_size):
# 解码当前序列的token IDs为字符串
decoded = self.tokenizer.decode(decoder_input_ids[i].tolist())
# 如果字符串中包含EOS标记,只取EOS之前的部分(去除生成的无意义内容)
if self.tokenizer.eos_token in decoded:
decoded = decoded.split(self.tokenizer.eos_token)[0]
preds.append(decoded)
return preds
20.6.2. 查看 Transformer 模型详情#
from lightning.pytorch.utilities.model_summary import ModelSummary
# 定义 Transformer 模型
model = Transformer(tokenizer, d_model, feedforward_size, encoder_max_length=encoder_max_length,
decoder_max_length=decoder_max_length - 1)
# 打印模型摘要详情
summary = ModelSummary(model, max_depth=2)
print(summary)
| Name | Type | Params | Mode | FLOPs | In sizes | Out sizes
---------------------------------------------------------------------------------------------------------------------------
0 | encoder | Encoder | 248 K | train | 6.9 M | [2, 7] | [2, 7, 128]
1 | encoder.token_emb | Embedding | 2.0 K | train | 0 | [2, 7] | [2, 7, 128]
2 | encoder.position_emb | PositionalEncoding | 0 | train | 0 | [2, 7, 128] | [2, 7, 128]
3 | encoder.layers | ModuleList | 246 K | train | 0 | ? | ?
4 | decoder | Decoder | 299 K | train | 6.3 M | [[2, 5], [2, 7], [2, 7, 128]] | [2, 5, 16]
5 | decoder.token_emb | Embedding | 2.0 K | train | 0 | [2, 5] | [2, 5, 128]
6 | decoder.position_emb | PositionalEncoding | 0 | train | 0 | [2, 5, 128] | [2, 5, 128]
7 | decoder.layers | ModuleList | 295 K | train | 0 | ? | ?
8 | decoder.output_layer | Linear | 2.1 K | train | 41.0 K | [2, 5, 128] | [2, 5, 16]
---------------------------------------------------------------------------------------------------------------------------
548 K Trainable params
0 Non-trainable params
548 K Total params
2.192 Total estimated model params size (MB)
38 Modules in train mode
0 Modules in eval mode
13.2 M Total Flops
20.6.3. 使用 Transformer 模型进行推理测试#
from dsxllm.util import print_generation_predictions
# 1️⃣ 创建一些测试问题和答案
questions = ["829+33", "58+136", "22+593", "243+269", "1+1"]
answers = ["862", "194", "615", "512", "2"]
# 2️⃣ 使用与训练时统一的数据处理方法对输入进行处理
question_encoded = encoder_transform(questions)
encoder_input_ids = question_encoded["input_ids"]
# 3️⃣ 使用模型进行预测
generated_texts = model.generate_batch(encoder_input_ids)
# 4️⃣ 输出预测结果
print_generation_predictions(questions, answers, generated_texts)
🎯 生成结果 (准确率: 0/5 = 0.00%):
+---------+--------+--------+------+
| 输入 | 真实值 | 预测值 | 标记 |
+---------+--------+--------+------+
| 829+33 | 862 | 73+6 | ☒ |
| 58+136 | 194 | 2=2 | ☒ |
| 22+593 | 615 | 73++ | ☒ |
| 243+269 | 512 | 73+6 | ☒ |
| 1+1 | 2 | 73+ | ☒ |
+---------+--------+--------+------+
在模型训练前,模型预测的正确率为 0,说明模型暂不具备加法计算的能力,在下一小节中,我们将训练模型,使它能够进行加法计算。
20.7. 本章小结#
这一章,我们使用之前实现的 Transformer 组件,分别实现了 Transformer Encoder 和 Transformer Decoder 模块,最后将它们组合起来,实现了完整的 Transformer 模型。在下一章,我们将对 Transformer 模型进行评估和优化,和之前基于 GRU 的 Seq2Seq 模型进行对比。
20.8. 答疑讨论#
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。